
Tech Tip: Use “Compare Strings” Command to Compare Hidden Characters
PRODUCT: 4D | VERSION: 19 | PLATFORM: Mac & Win
Published On: January 16, 2023
The 4D language and database engine use the unicode standard to make the software accessible to users worldwide—with more than 65,000 number values to accommodate for various characters across different speaking languages as well as symbols and icons. Not all unicode number values have a visible character attached to itself; and when these characters are stored within 4D, the program recognizes that a character is present, but does not visually show that character. This can cause problems when comparing text values using the string comparison operators.
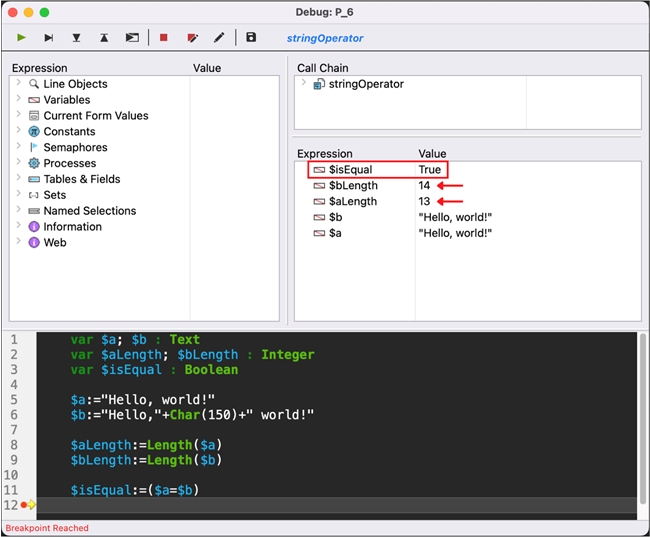
As you can see in the debugger above, $a and $b visually look the same but are inherently different. The comparison operator compares what is human readable, while the text length is dictated by what 4D internally interprets.
In cases where you would like to take these hidden characters into consideration, it is better to instead use the Compare Strings command in combination with the sk char codes constant.
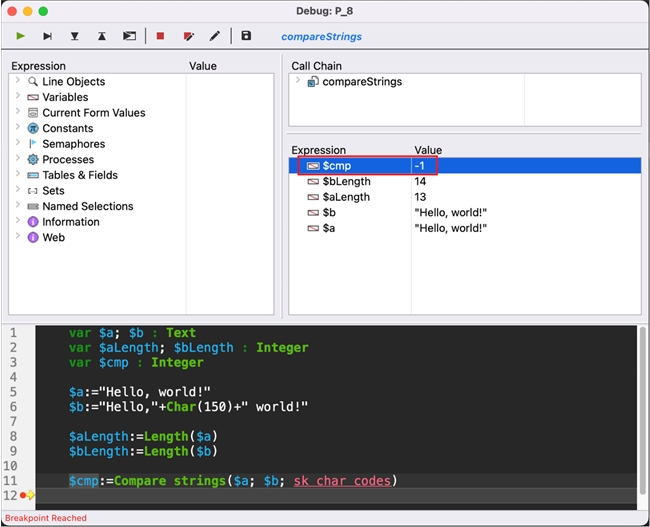
Here, you can see that the command recognizes the two strings are inherently different, as shown in the -1 return value.
In general, it is good to first have filters for any imported data, but this approach can act as an extra layer of security while working with text data.
Compare Strings Documentation: https://doc.4d.com/4Dv19/4D/19.5/Compare-strings.301-6136770.en.html
As you can see in the debugger above, $a and $b visually look the same but are inherently different. The comparison operator compares what is human readable, while the text length is dictated by what 4D internally interprets.
In cases where you would like to take these hidden characters into consideration, it is better to instead use the Compare Strings command in combination with the sk char codes constant.
Here, you can see that the command recognizes the two strings are inherently different, as shown in the -1 return value.
In general, it is good to first have filters for any imported data, but this approach can act as an extra layer of security while working with text data.
Compare Strings Documentation: https://doc.4d.com/4Dv19/4D/19.5/Compare-strings.301-6136770.en.html