
Tech Tip: Token Cost Control in 4D AIKit
PRODUCT: 4D | VERSION: 20 R | PLATFORM: Mac & Win
Published On: November 12, 2025
When using the OpenAI API through 4D AIKit, it’s important to keep in mind that usage is billed based on tokens, not just the number of requests. Both the prompt (input) and the response (output) consume tokens. If no limits are set, costs can increase quickly, especially with long conversations or high volumes of requests.
To avoid this, always define a token limit (max_tokens) when generating responses.
Optimizing prompts helps reduce token usage while getting clear, precise answers. Shorter prompts with specific instructions allow the model to focus on what matters most. Here’s a “before and after” illustration:
Before (uses more tokens):
"Please explain in full detail everything about arrays in 4D with many examples."
After (efficient):
"Explain how to use arrays in 4D with two examples. Max 120 words."
Shorter prompts + clear instructions = fewer tokens spent.
To avoid this, always define a token limit (max_tokens) when generating responses.
Setting Token Limits
| var $messages : Collection var $options : Object var $result : Object $messages:=[{role:"user"; content:"Explain quantum physics"}] $options:={model:"gpt-4o-mini"; max_tokens:150} // Limit response size $result:=$client.chat.completions.create($messages; $options) |
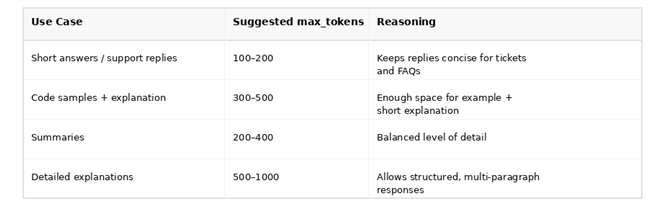
Recommended Limits by Use Case
Prompt Optimization Example
Optimizing prompts helps reduce token usage while getting clear, precise answers. Shorter prompts with specific instructions allow the model to focus on what matters most. Here’s a “before and after” illustration:
Before (uses more tokens):
"Please explain in full detail everything about arrays in 4D with many examples."
After (efficient):
"Explain how to use arrays in 4D with two examples. Max 120 words."
Shorter prompts + clear instructions = fewer tokens spent.